Approach
Although every performance problem is different, a structured approach ensures the ground rules are clear and avoids wasting time due to misconceptions.
People call me when they have hard problems, ones they can't figure out on their own. Probably, they tried a bunch of things already, and the problem didn't go away. My task is to find the thing they didn't spot, either somewhere they didn't look, or by looking in a different way. I take a strictly facts-based approach.
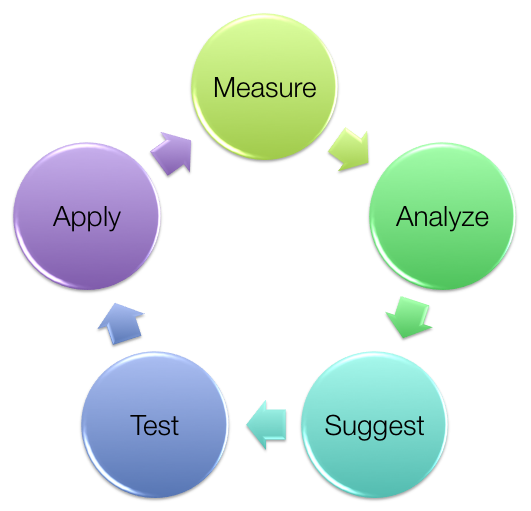
- First, you have to state what the problem is, and say what ‘good’ looks like. For instance “the time from order request to acknowledgement is over 2 seconds, and I need it to be under 0.5 seconds”. You may want to get fancy with statistics, e.g. “I want the 97th percentile to be under 0.5 seconds and the 99th percentile under 1 second”, but the main point is to be clear what we are talking about, and also to know when to stop optimising.
- Then, we measure. What, exactly, is taking 2 seconds? What is it doing in that time? Is it chewing up CPU, or waiting for something else? What is the something else doing? And so on.
I much prefer to measure the real, live, system where the problem is happening, and not a test or dev environment. Some data-gathering is entirely non-intrusive, while some will place a little extra load on the system. This is a price we must pay to know the truth.
- Analyze the data. Is there a pattern to it? Is it always slow first thing in the morning? Is it slow when several requests come at once? If there is no pattern like that, does it correlate with something else going on in the system? If we can't spot anything, we may have to go back a stage and gather some more data.
- Suggest a cause for the performance problem. This is the scientific method: we make a hypothesis, then we try to find data that supports the hypothesis. If we already have data that refutes this hypothesis, we need a better hypothesis.
It may be that at this stage I can see no room for improvement within the system. This can happen; I'm not all-powerful. There may be scope for improvement upstream or downstream, or to re-cast the problem so we break it down into smaller pieces, but those require wider discussion.
If, however, we have a good hypothesis about a bottleneck within the system, we move on to experiment...
- We test the hypothesis. This is usually done in a non-production environment, recreating the scenario as best we can. We control the experiment, repeating the test with and without the suggested modification, to demonstrate that it does indeed have an effect. Also we run regression tests to see if this change makes anything else worse.
If the test says this change is not good enough, we loop back to suggest a further change. We may need further measurements to understand what was wrong with the original hypothesis and thus derive a better hypothesis.
- Finally, if all looks good in test, we apply the change in production. We measure carefully once more, to determine the overall effectiveness of the change; if sufficient then we celebrate, if not then we loop round again looking for further improvements. It is not uncommon for one bottleneck to hide a second, so that by removing the first you merely move the problem elsewhere.
Next Step
If you would like to discuss how these techniques could improve your business, contact [email protected]